YOLO V1学习笔记
Table of Contents
YOLO: You Only Look Once #
本文是教学视频【精读AI论文】YOLO V1目标检测,看我就够了的学习笔记.
YOLO是什么 #
Yolo是用来解决计算机视觉领域中目标检测问题的机器学习模型.
计算机视觉需要解决什么问题 #
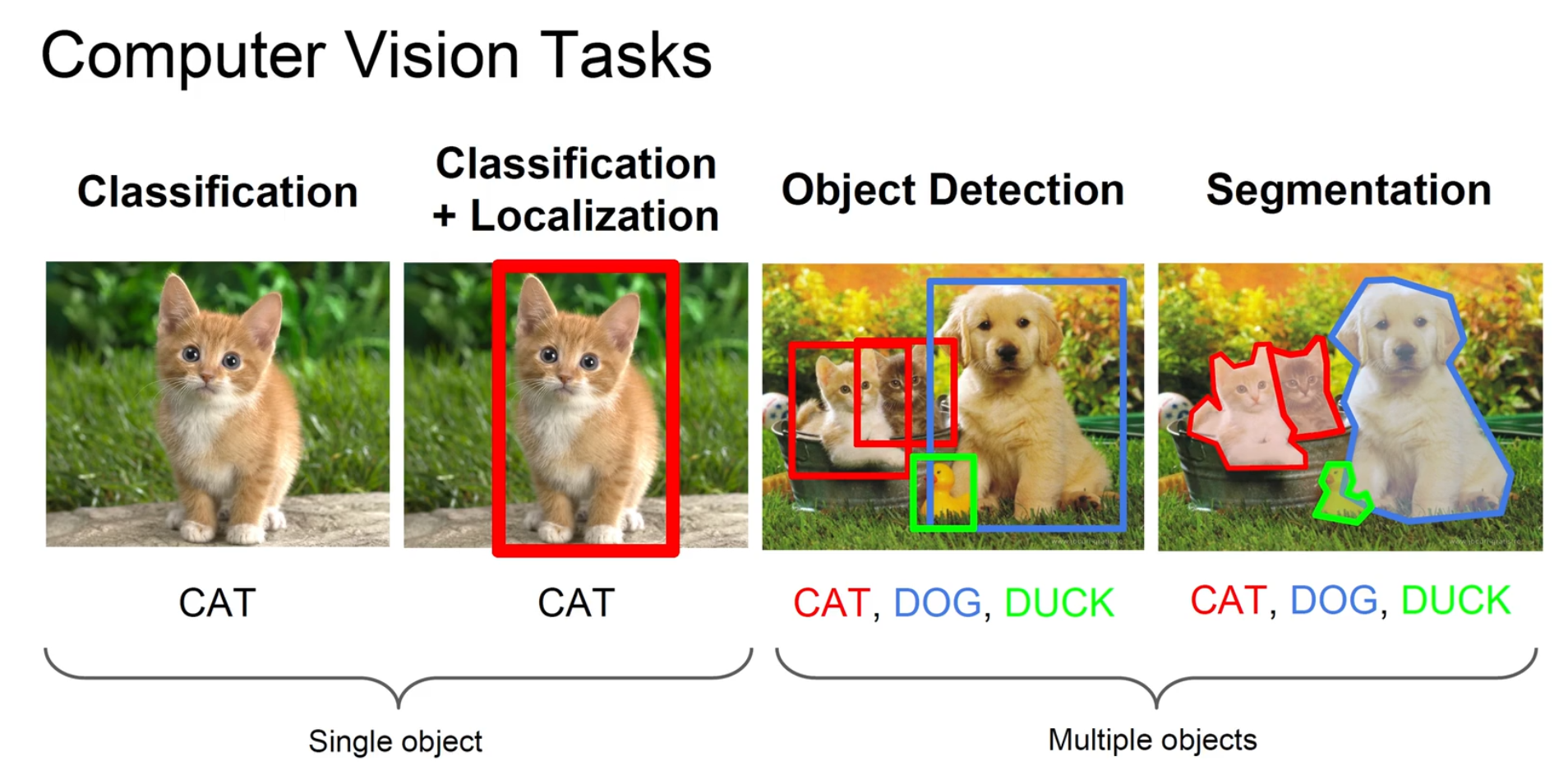
分类, 分类 + 定位, 目标检测, 分割
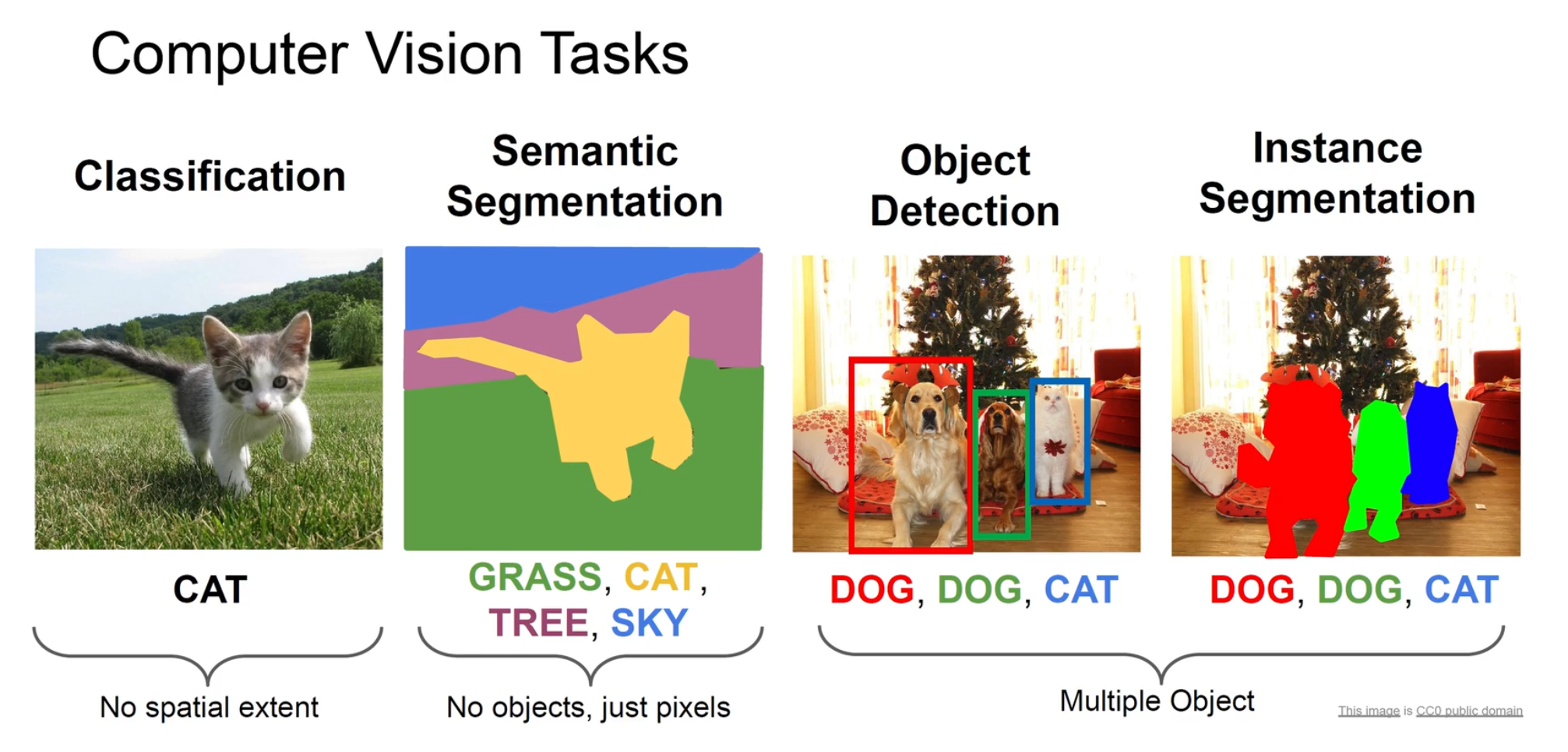
分类, 语义分割, 目标检测, 实例分割
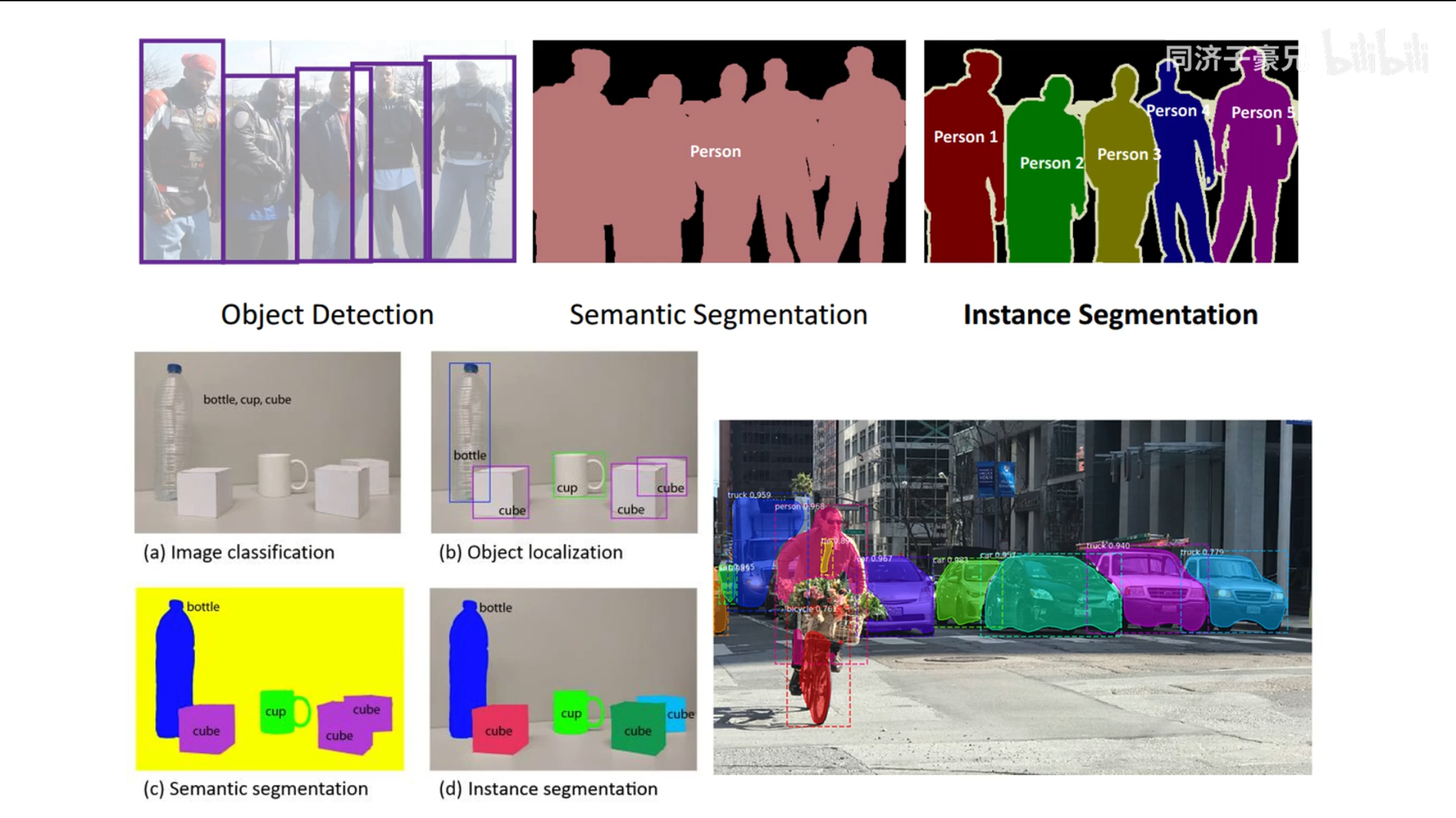
更清晰的例子, 可以看出实例分割是最难的
目标检测: 单阶段模型与双阶段模型 #
- 单阶段模型: 端到端, 直接提取物体边界
- 双阶段模型: 先给出一些候选框, 再对候选框进行识别与微调
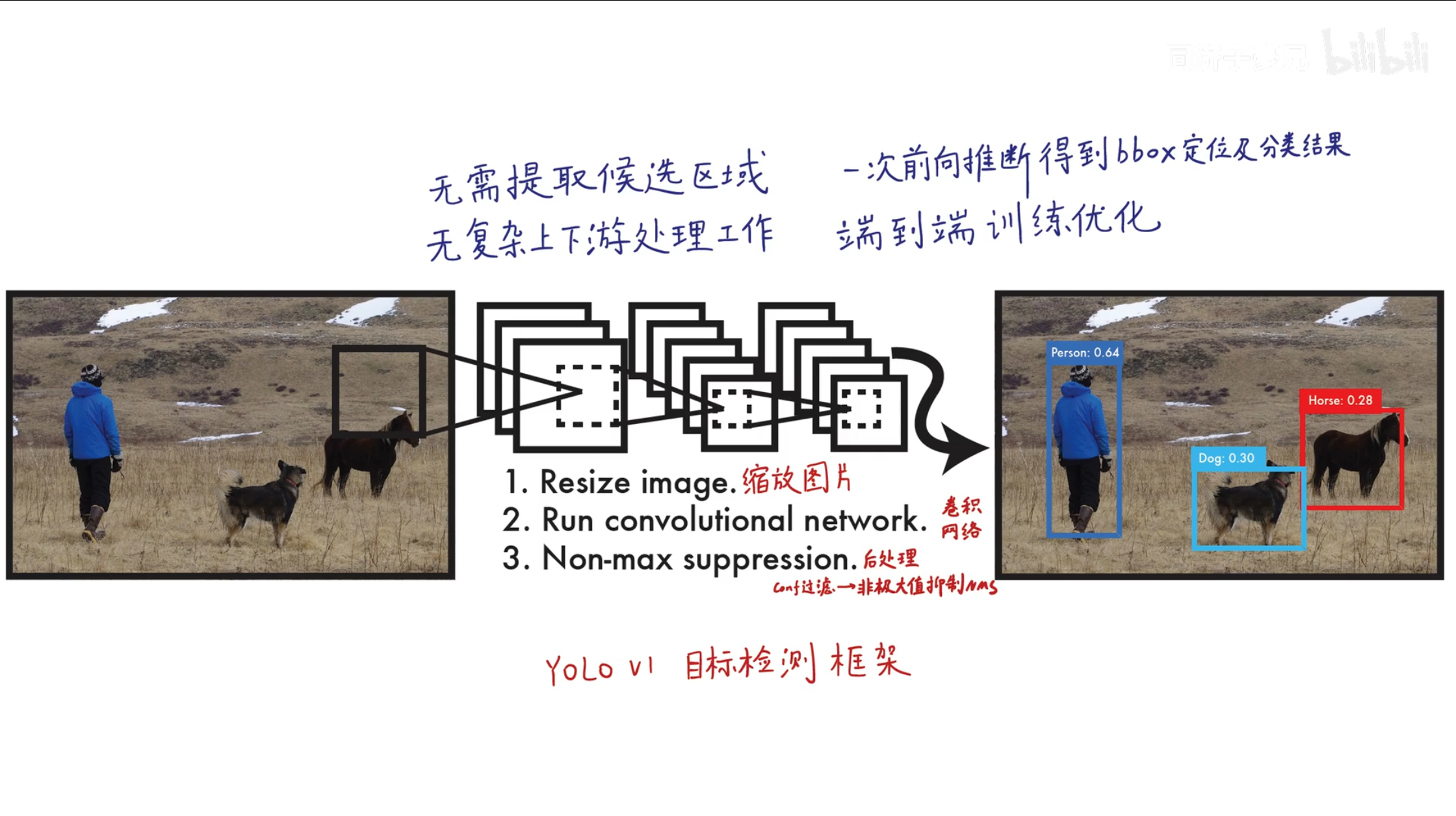
YOLO属于单阶段模型
YOLO V1: 预测阶段(前向推断) #
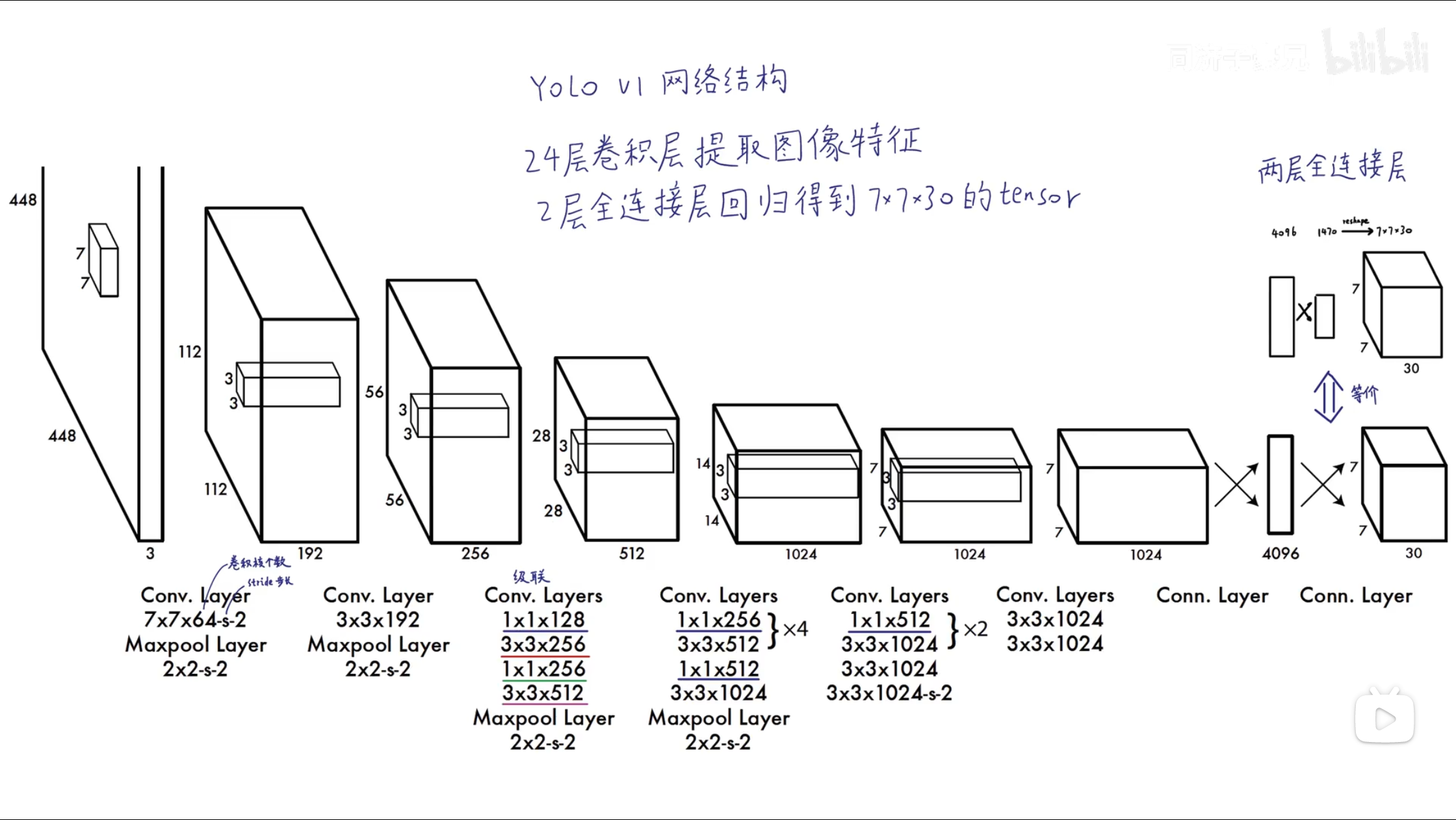
YOLO V1网络结构
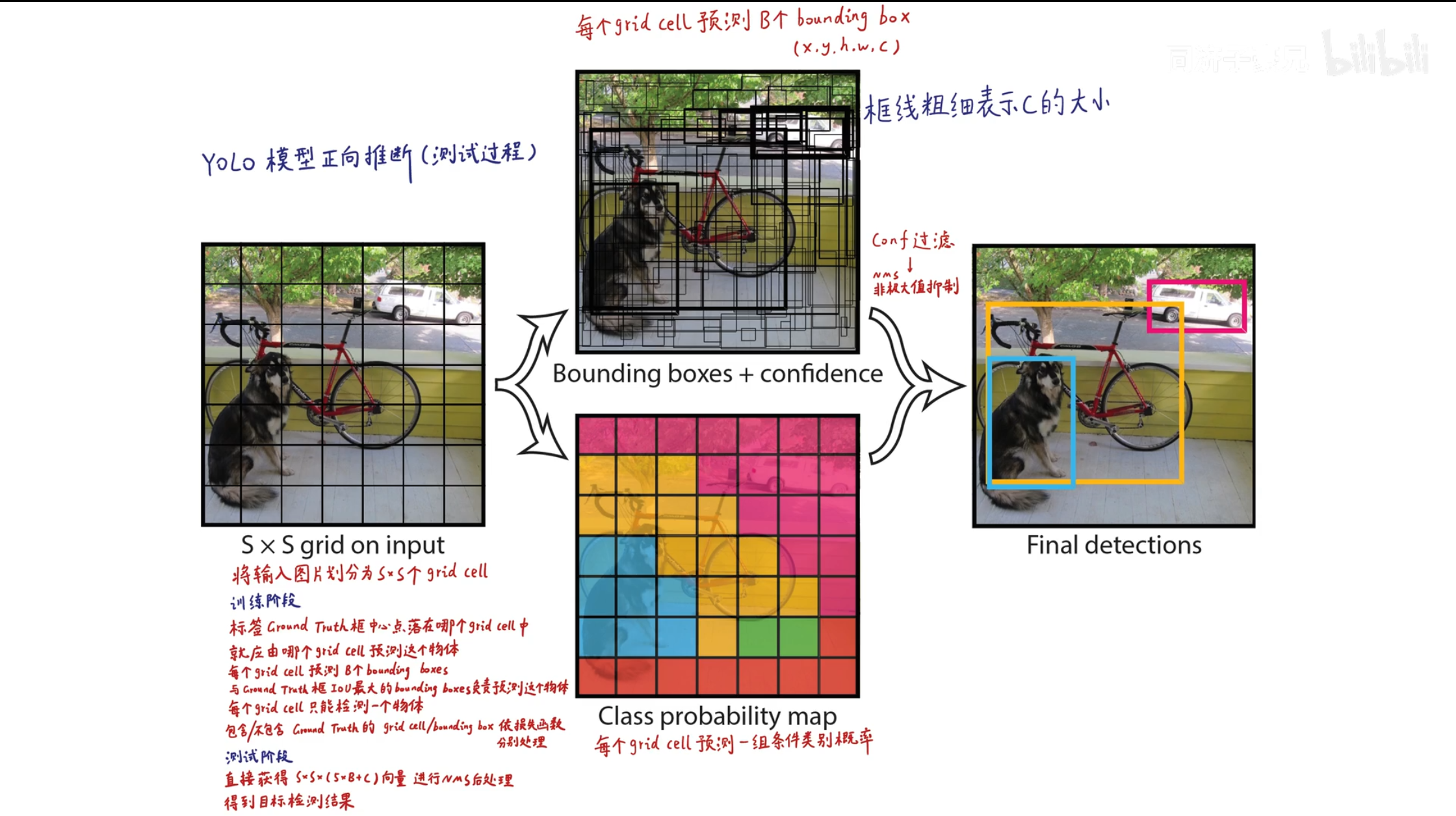
YOLO V1预测阶段
- 把图片转化成正方形, 切割成 $s × s$ 个Grid Cell, 对于每个Grid Cell, 会生成 $B$ 个中心点在其内部的矩形框, 预测如果拥有物体, 物体是某一类的概率 , 概率越大框越粗. 根据物体类别划分Grid Cell, 根据置信度决定矩形框粗细, 两者结合最后处理得到预测结果.
YOLO V1: 预测阶段后处理 #
我们的目标 #
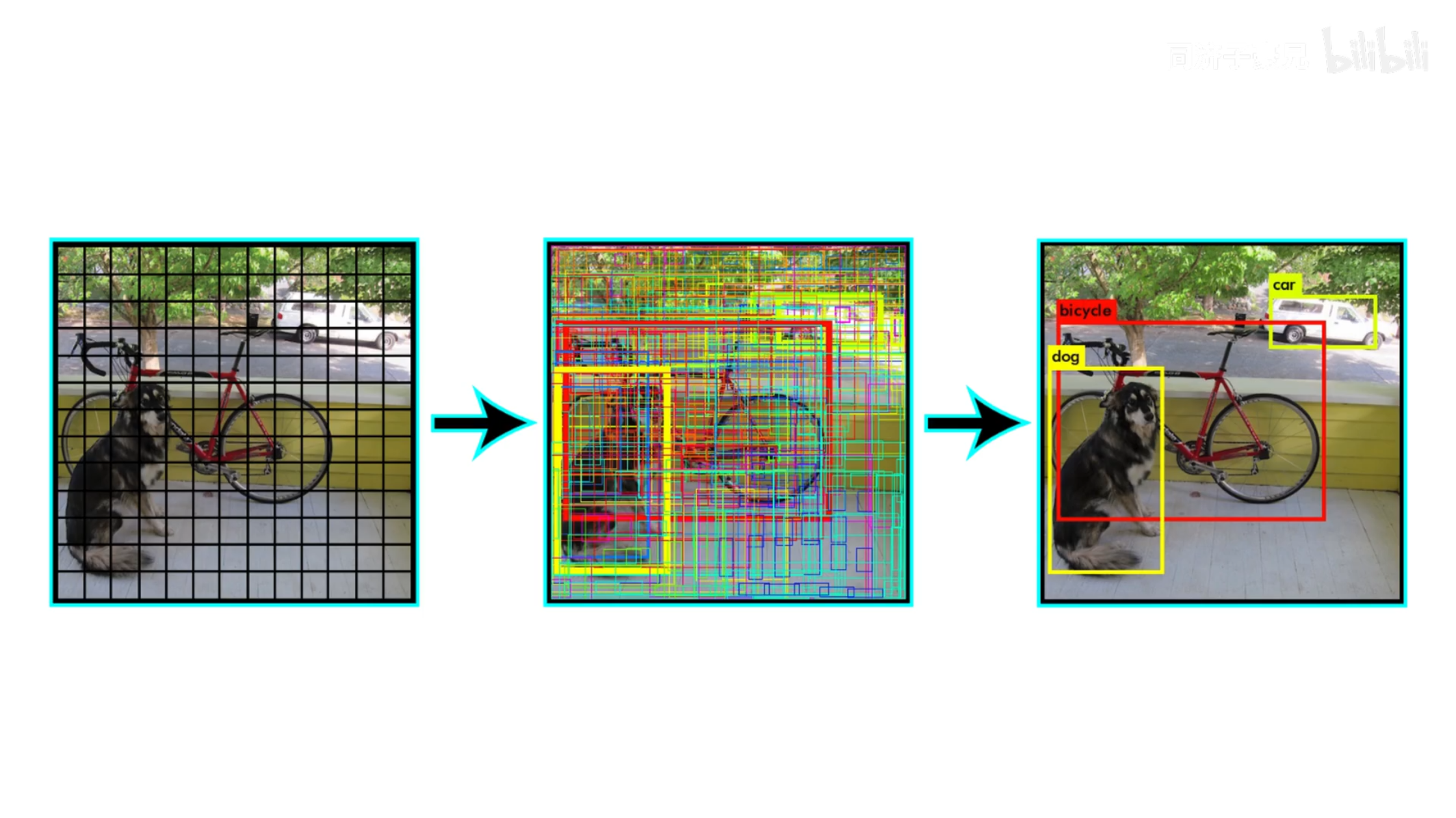
从诸多矩形框中得到最终结果
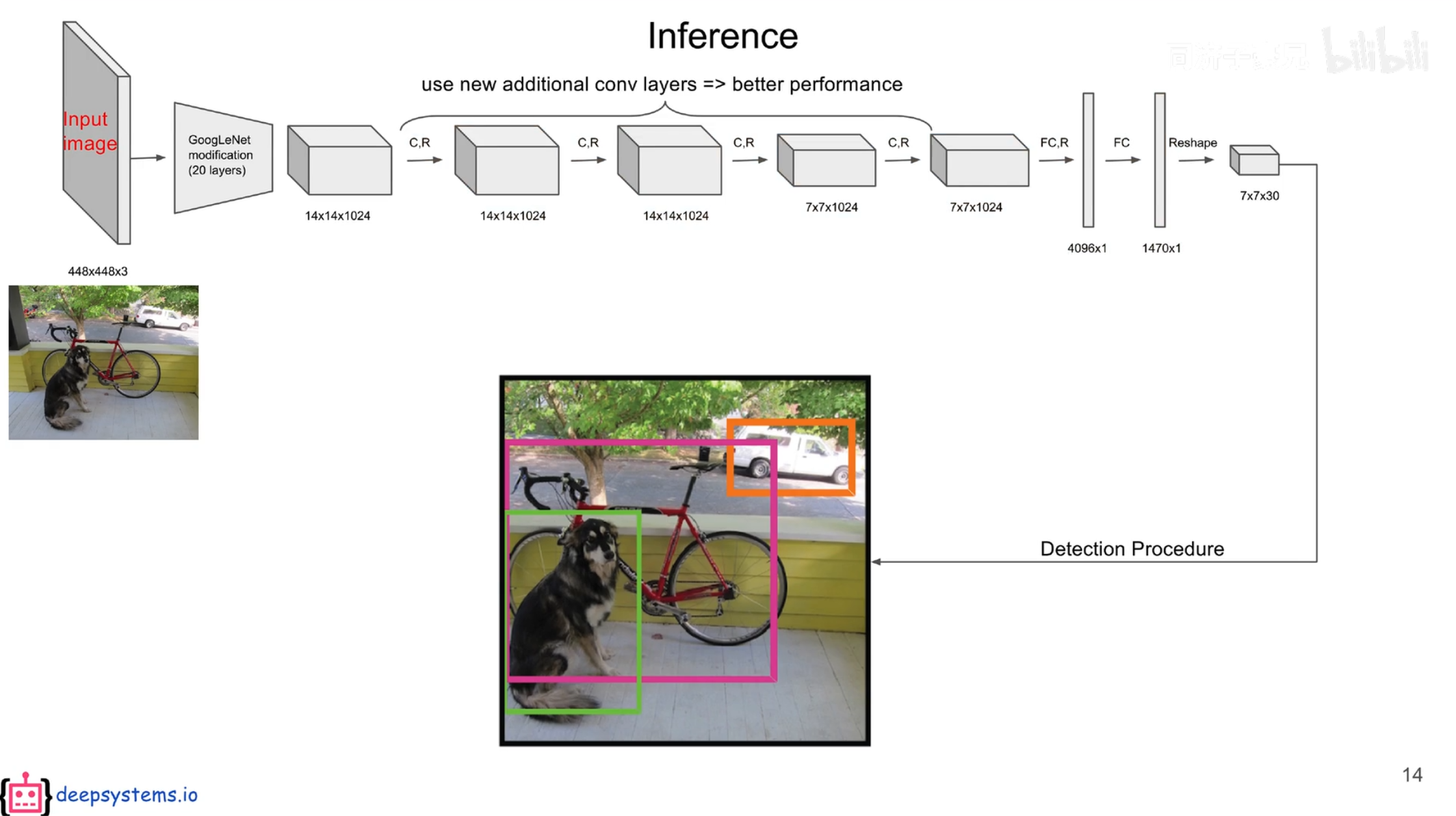
把模型中7×7×30的向量转化为最终预测结果
预测得到的初步结果是什么 #
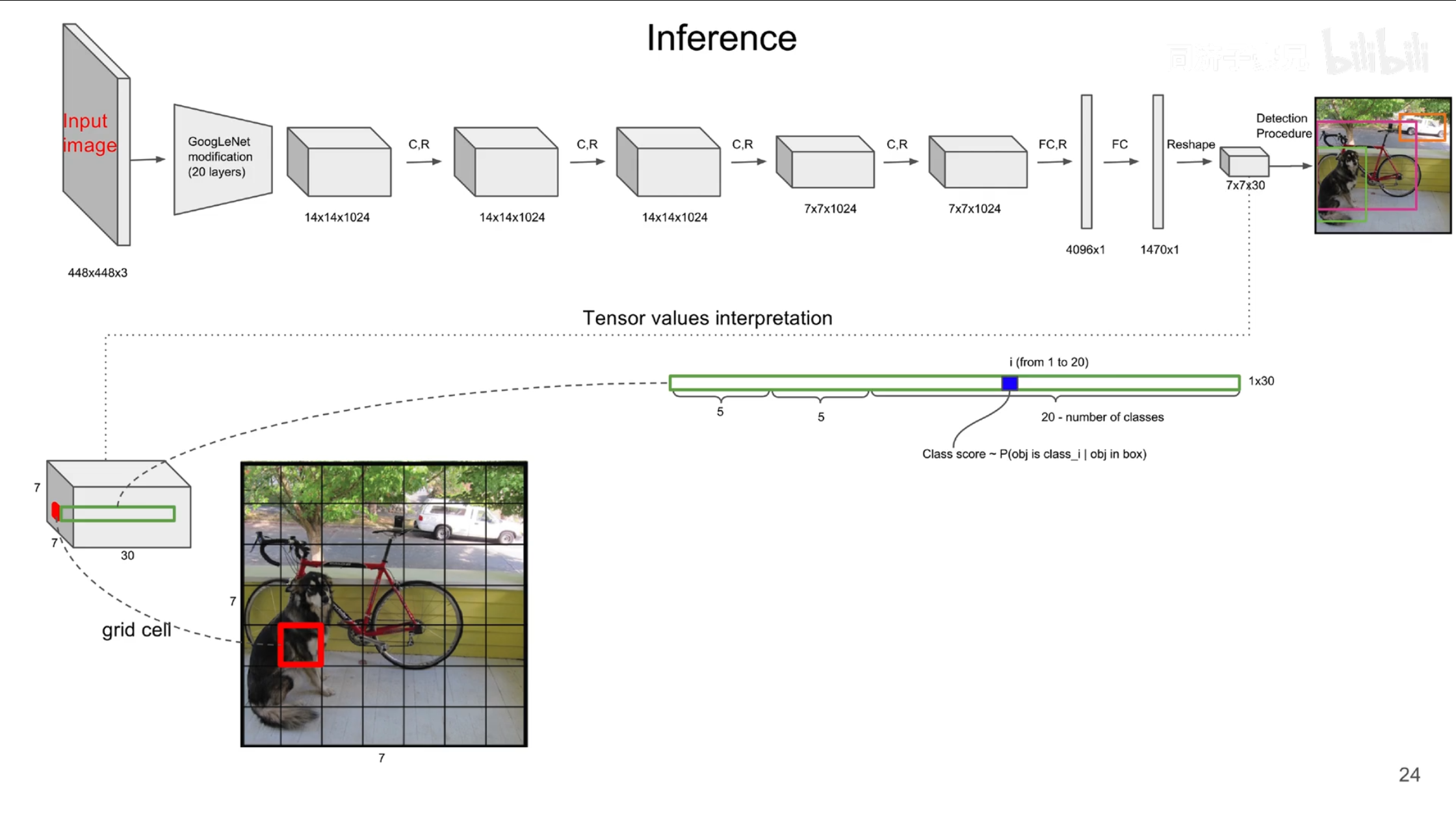
7×7×30向量结构
$7 × 7 × 30$ 向量的含义:
- $7 × 7$ 个Grid Cell
- $30 = 2 × 5 + 20$ :
- $2$ 个预测矩形框, 每个矩形框拥有 $5$ 个参数: 中心点的归一化横纵坐标 $x, y$, 矩形框的归一化宽和高 $w, h$ , 预测框置信度 $P(obj\ in\ box))$;
- $20$ 个类别, 分别为预测各个类别的条件概率 $P(obj\ is\ class_i|obj\ in\ box)$
把$P(obj\ is\ class_i|obj\ in\ box)$ 与 $P(obj\ in\ box)) $ 相乘, 得到 $P(obj\ is\ class_i)$ , 一共获得 $7 × 7 × 2$ 个 $20$ 维向量.
对于上一步获得的 $7 × 7 × 2$ 个 $20$ 维向量, 我们对于其第一维设定一个抹零的阈值, 抹零后进行排序, 再进行NMS处理.
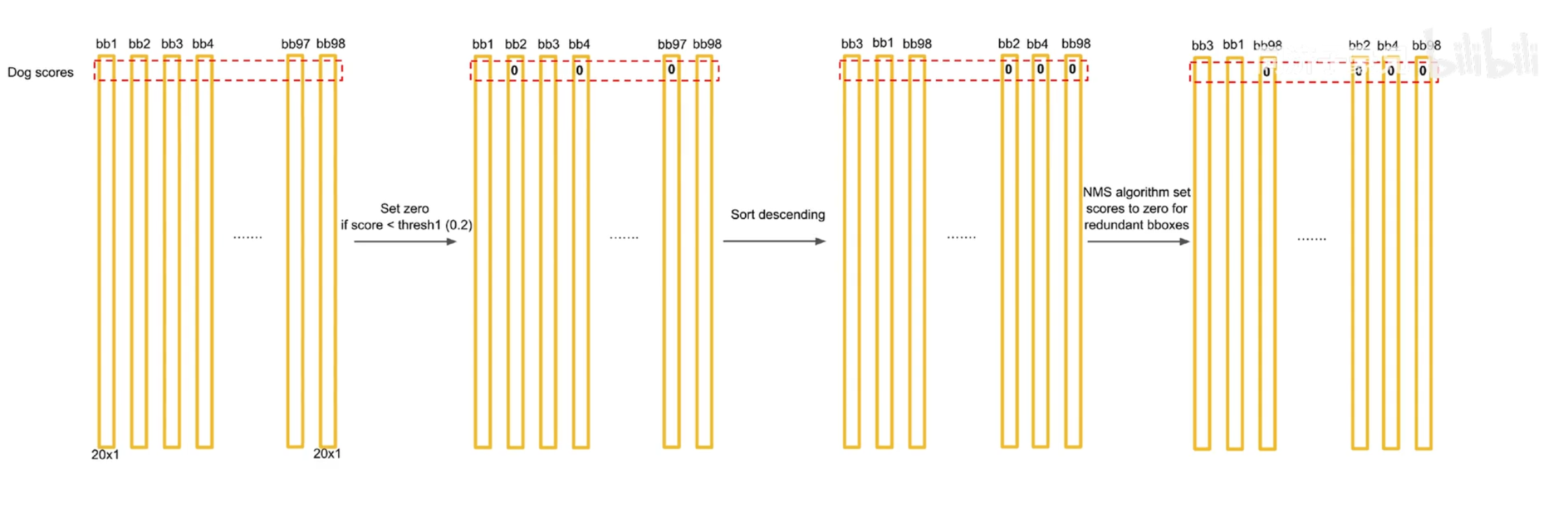
向量操作
NMS #
NMS(Non Maximum Suppression): 非极大值抑制, 顾名思义就是抑制不是极大值的元素, 搜索局部的极大值.
去重 #
对于某个类别, 我们把矩形框与概率最大的矩形框进行比较, 如果两者IOU(交并比)大于一定阈值, 就认为这两个矩形框识别的是一个物体, 把概率低的矩形框舍弃, 赋值为 $0$ . 与最大的比较之后再与次大的比较, 依此类推.

去掉重复的矩形框
注意NMS只在预测阶段使用.
YOLO V1: 训练阶段 #

YOLO V1预测与实际标注
如上图所示, 对于Ground Truth中心点落在的Grid Cell, 我们要让与其交并比大的那个预测矩形框尽可能拟合它. 实际上, YOLO V1的损失函数如下图所示:
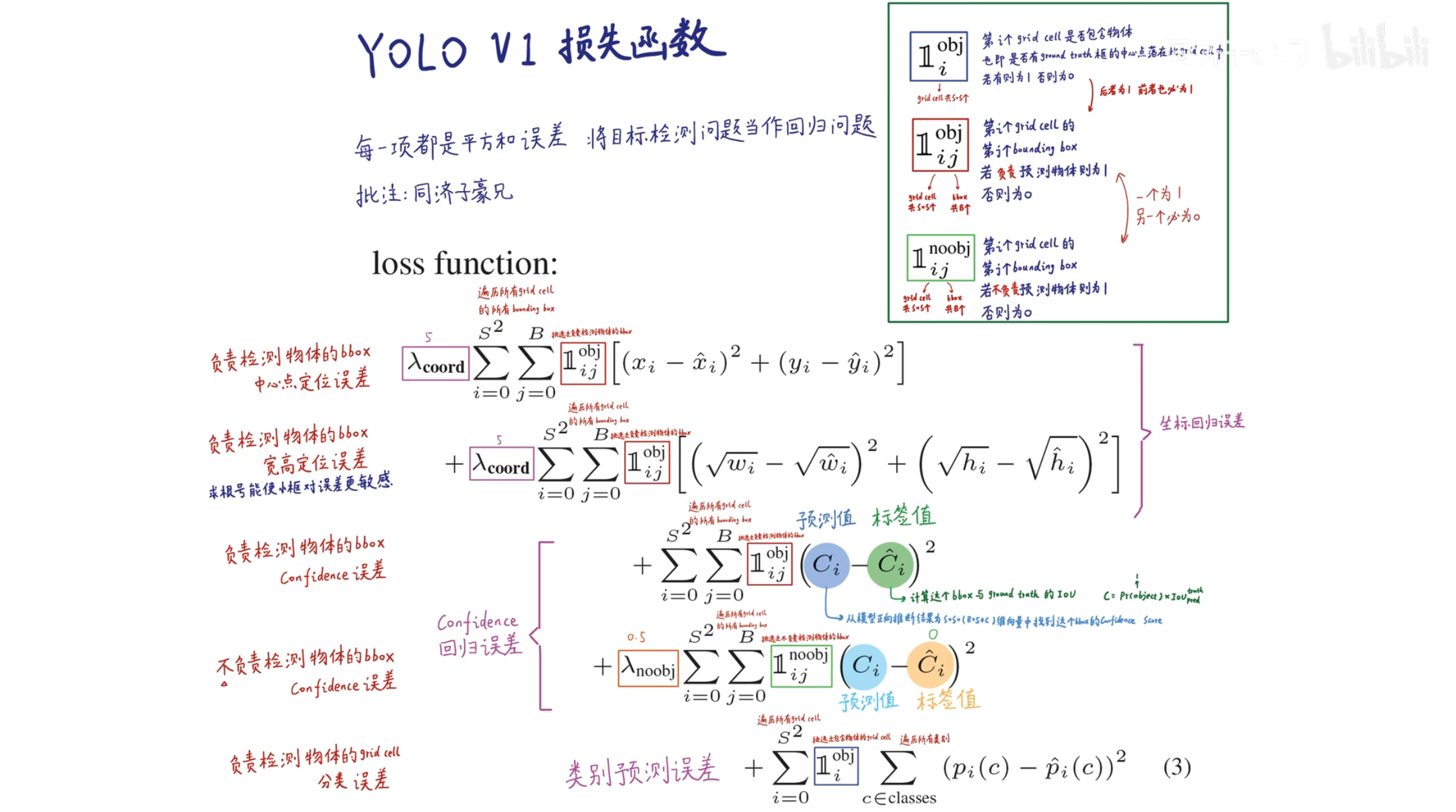
YOLO V1损失函数
损失函数的设计思想是把预测当作回归问题解决, 主要有 $5$ 项组成:
- 负责检测物体的矩形框的中心点定位误差
- 负责检测物体的矩形框的宽高定位误差
- 负责检测物体的矩形框的置信度误差
- 不负责预测物体的置信度误差
- 负责检测物体的分类误差